The internet has become an integral aspect in the modern world. With just a few keystrokes, we can access a world of information, services, and entertainment.
But, have you ever wondered what happens when you type an address to any website such as when you type “https://www.google.com” or “https://lyonec.com” in your browser and press enter?
Well, a number of processes take place within that short period. In this article, we’ll explore the inner workings of the internet from a technological perspective, taking you through the journey of how your browser communicates with the Google servers to retrieve the requested web page. We’ll unravel the complex processes and technologies involved in turning your simple request into a fully-rendered web page.
Parts of a URL
To navigate the vast expanse of the internet, we rely on domain names and URLs as our guides. A domain name serves as a human-readable identifier for a specific website, while a URL (Uniform Resource Locator) is the complete address that specifies the location of a particular resource on the web.
Let’s break down a URL using the example of “https://www.google.com“.

- https://
The first part, “https://“, indicates the protocol used for communication. In this case, it’s HTTPS, which stands for Hypertext Transfer Protocol Secure, providing a secure connection between your browser and the web server. Other common protocols include HTTP for regular web pages and FTP for file transfers.
The domain name, “www.google.com,” is the next component. It consists of three parts: the subdomain (www), the second-level domain (google), and the top-level domain (com).
- www
The subdomain, “www,” often denotes the World Wide Web, but it can be customized to represent various sections of a website.
The second-level domain, “google,” identifies the specific website or organization
- com
The top-level domain, “com,” signifies a commercial entity.
Domain names are registered and managed by organizations called domain registrars, and there are numerous top-level domains available, such as .com, .org, .net, and country-specific domains like .uk or .de. The Internet Corporation for Assigned Names and Numbers (ICANN) oversees the assignment and maintenance of domain names globally.
Domain Name System (DNS)
When you enter a domain name in your browser, your computer needs to translate it into an IP address to establish a connection with the corresponding web server.
IP address is a numerical representation that allows it to establish a connection with the web server hosting the desired website. This process of translating domain names to IP addresses is known as DNS resolution. This translation is performed by the Domain Name System (DNS).
What is Domain Name System (DNS)?
The DNS is like a massive distributed phone book that maps domain names to their respective IP addresses. It enables the browser to locate the web server responsible for hosting the requested website.
The DNS resolution process involves multiple steps. First, your computer checks its local cache for a previously resolved IP address for the given domain name. If it’s not found, it sends a query to a DNS resolver, typically provided by your internet service provider (ISP) or a public DNS server like Google DNS or Cloudflare DNS.
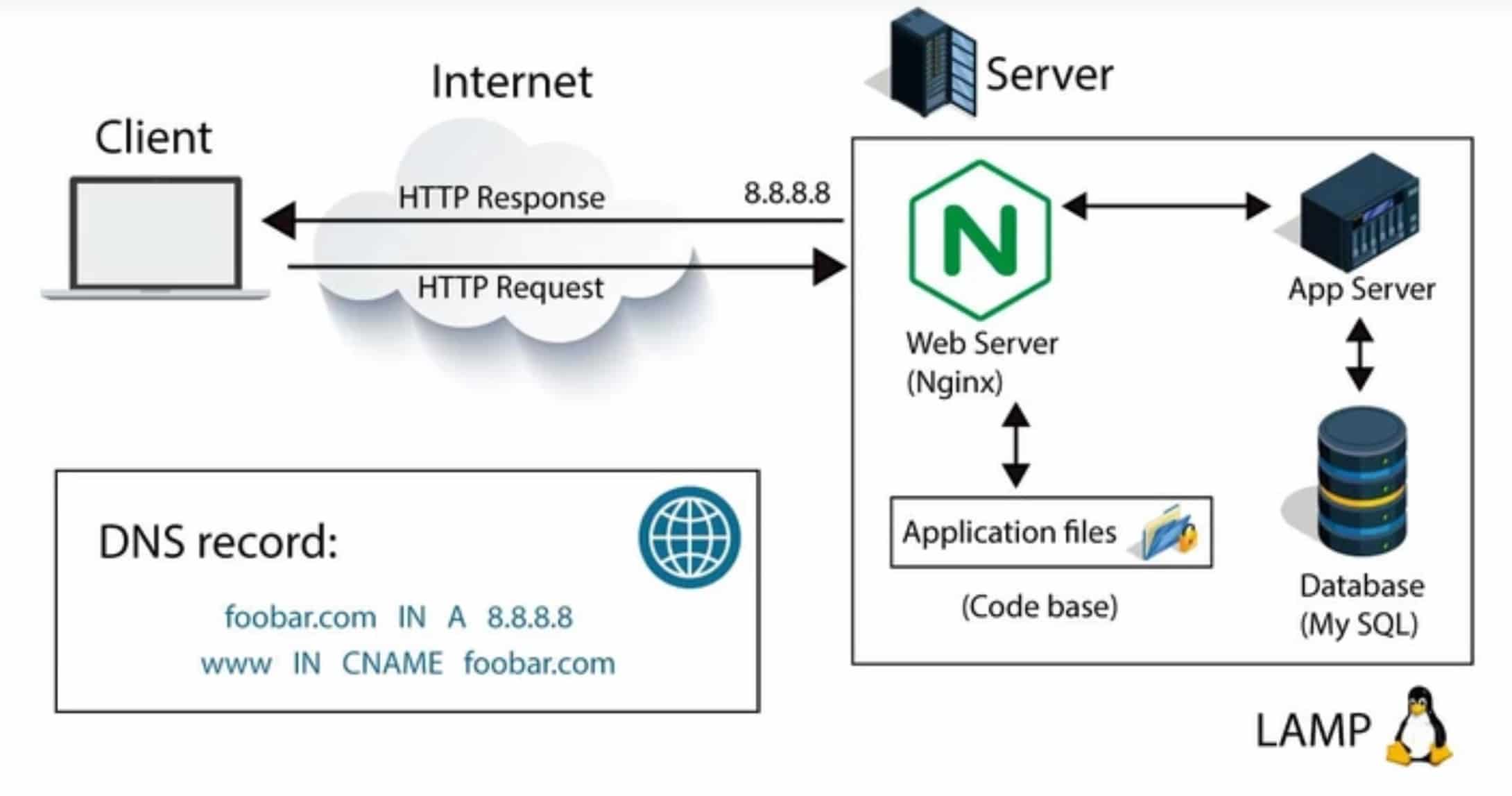
The resolver then interacts with the DNS hierarchy, starting with the root DNS servers. These servers provide information about the top-level domain servers (.com, .org, etc.). The resolver then contacts the appropriate top-level domain server, which directs it to the authoritative name server for the specific domain. The authoritative name server holds the IP address associated with the domain name, and the resolver retrieves it and returns it to your browser.
With the IP address in hand, your browser can now initiate a connection with the web server hosting the requested website. The server responds by sending back the requested web page, which your browser then renders for you to interact with.
Establishing a Connection
Now that your computer has obtained the IP address of the web server hosting the desired website through DNS resolution, it’s time to establish a connection between your browser and the server. This process relies on two fundamental protocols: the Hypertext Transfer Protocol (HTTP) and the underlying TCP/IP protocol suite.
HTTP is the protocol that governs the communication between web browsers and web servers. It defines how requests and responses are structured and exchanged. When you enter a URL in your browser, it sends an HTTP request to the server, specifying the desired web page or resource.
Underneath HTTP, the TCP/IP protocol suite provides the foundation for reliable data transmission over the internet. TCP (Transmission Control Protocol) breaks down the data into smaller packets, numbers them for sequencing, and ensures their reliable delivery to the destination. IP (Internet Protocol) handles the addressing and routing of these packets across the internet.
Dynamic Host Configuration Protocol (DHCP) is responsible for automatically assigning IP addresses to devices on a network. It automates the assignment of IP addresses and other network configuration parameters to devices on a network. Instead of manually configuring IP addresses on each device, DHCP dynamically assigns and manages IP addresses, making network administration more efficient.
When a device connects to a network, it sends a DHCP request to a DHCP server, which then offers an available IP address to the device. DHCP ensures that each device receives a unique and valid IP address to facilitate network communication.
To establish a connection, your browser initiates a TCP three-way handshake. The handshake involves three steps:
- SYN: Your browser sends a SYN (synchronize) packet to the web server, indicating its desire to establish a connection.
- SYN-ACK: The web server responds with a SYN-ACK (synchronize-acknowledgment) packet, acknowledging the request and indicating its willingness to establish a connection.
- ACK: Your browser sends an ACK (acknowledgment) packet back to the server, confirming the connection establishment.
Once the three-way handshake is complete, a reliable connection has been established between your browser and the web server. This connection allows for the transmission of HTTP requests and responses.
At this point, your browser can send the HTTP request, which includes the necessary information for the server to process and fulfill your request. The request may include additional headers, such as cookies or user agent information, to provide context and personalize the interaction.
Upon receiving the request, the web server processes it, performing tasks such as handling authentication, retrieving data from databases or external services, and generating the appropriate response.
Once the web server has processed the request, it generates an HTTP response containing the requested web page or resource. This response is then sent back to your browser over the established TCP connection.
HTTP Versus HTTPS
When you type a URL in your browser and press Enter, your browser initiates an HTTP (Hypertext Transfer Protocol) request to the web server hosting the desired web page.
HTTP is the protocol that governs the communication between the client (your browser) and the server. The HTTP request is the mechanism through which your browser requests specific resources from the server.
An HTTP request consists of several components:
- Request Method: This indicates the type of request being made, such as GET (retrieve a resource), POST (send data to be processed), PUT (update a resource), DELETE (remove a resource), and more.
- Request URL: The URL specifies the location of the resource being requested, including the domain, path, and any query parameters.
- Headers: HTTP headers provide additional information about the request, such as the browser type, accepted content types, authentication credentials, and cookies.
- Request Body: Some request methods, such as POST, may include a request body that contains data to be sent to the server.
Let’s walk through the process of an HTTP request when accessing “google.com”:
- Your browser sends an HTTP GET request to the IP address obtained from the DNS resolution of “google.com.”
- The request includes the following components:
- Request Method: GET
- Request URL: https://www.google.com
- Headers: These may include information about the browser type, accepted content types, and cookies.
- Request Body: Since this is a GET request, there is typically no request body.
- The request is transmitted over the established TCP connection between your browser and the web server.
- The web server hosting “google.com” receives the request and processes it.
- The server examines the request method and URL to determine which resource is being requested, in this case, the default web page of Google.
- The server generates an appropriate HTTP response, which includes the requested web page (HTML), status codes (e.g., 200 for success), and response headers (e.g., Content-Type, Cache-Control).
HTTPS
It’s important to mention that in the case of accessing websites over a secure connection, such as “https://www.google.com,” the communication is encrypted using the HTTPS protocol. HTTPS stands for Hypertext Transfer Protocol Secure, and it adds an extra layer of security by encrypting the data exchanged between your browser and the server.
With HTTPS, the HTTP request and response are encrypted using SSL/TLS (Secure Sockets Layer/Transport Layer Security) protocols, ensuring that the data remains private and protected from eavesdropping or tampering. This encryption provides a secure and trusted communication channel between the client and the server.
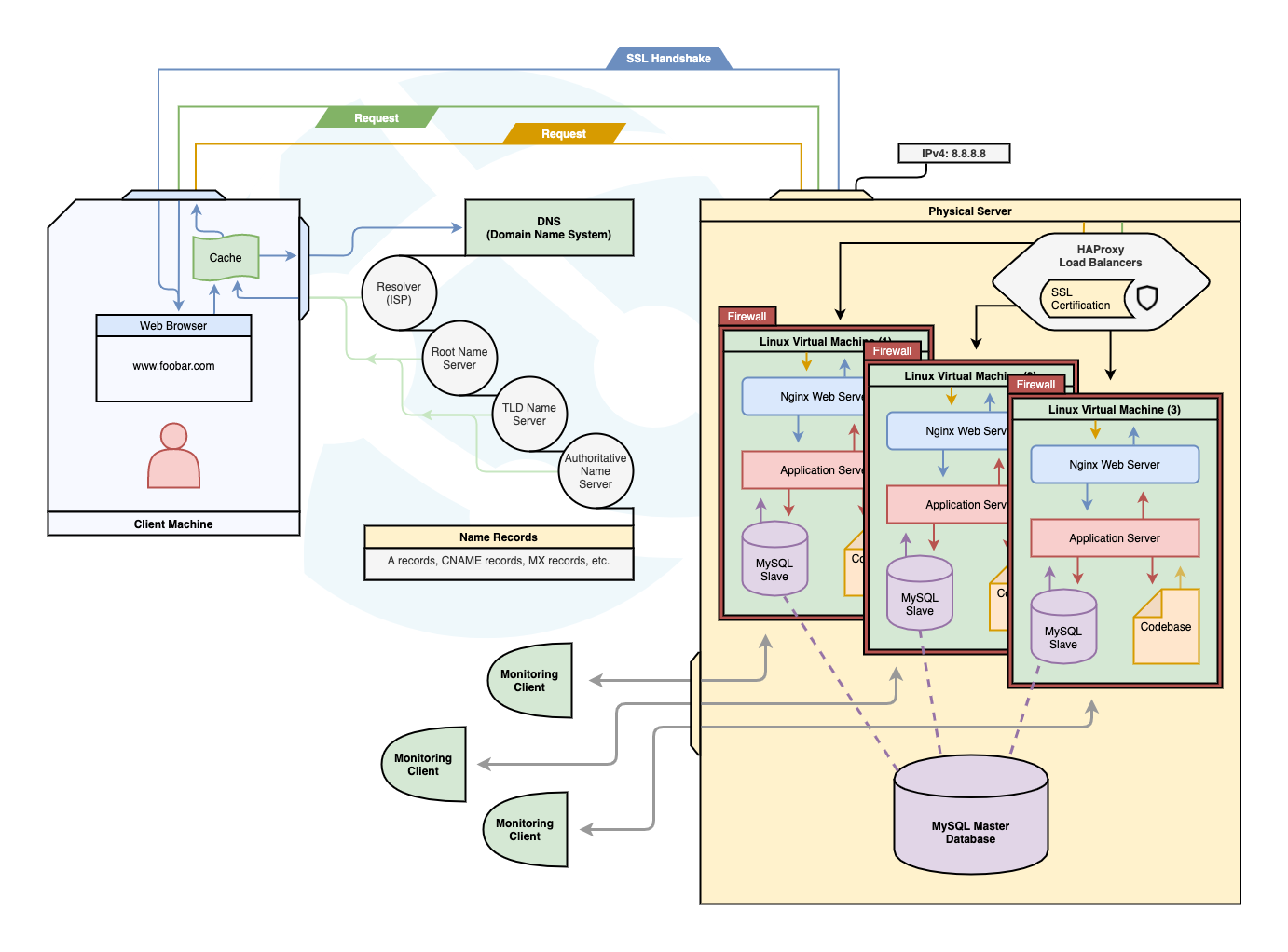
Load Balancing
It’s worth noting that in scenarios with high traffic or multiple web servers, load balancing comes into play. Load balancers such as HAproxy distribute incoming requests across multiple servers to ensure efficient utilization and prevent overload.

They employ various algorithms to determine how requests are distributed, such as round-robin, least connection, or least latency. Load balancing helps improve performance, scalability, and fault tolerance of web applications. It is a fundamental concept in building robust and scalable web applications.
Load Balancing Techniques
Load balancing algorithms are used to distribute incoming network traffic across multiple servers or resources to optimize performance, maximize resource utilization, and ensure high availability. Here are some commonly used load balancing algorithms:
- Round Robin: This distributes requests in a cyclic manner to each server in a sequential order. It treats all servers equally and does not take into account the server’s current load or capacity.
- Weighted Round Robin: Similar to Round Robin, but assigns different weights to servers based on their capacity or processing power. Servers with higher weights receive a proportionally larger share of requests.
- Least Connection: This technique directs incoming requests to the server with the fewest active connections at the time. It takes into account the current load on each server and aims to distribute requests evenly.
- Weighted Least Connection: Similar to Least Connection, but servers are assigned different weights based on their capacity. Servers with higher weights can handle more concurrent connections and receive a proportionally larger share of incoming requests.
- IP Hash: The algorithm calculates a hash value based on the source IP address of the incoming request and uses that value to determine which server should handle the request. This ensures that requests from the same IP address are consistently directed to the same server.
- Least Response Time: This algorithm measures the response times of servers and directs the request to the server with the lowest current response time. It dynamically adjusts to changing server conditions and aims to send requests to the fastest server.
- Adaptive Load Balancing: It continuously monitors server performance and adjusts the load distribution based on real-time feedback. It takes into account factors such as server capacity, response time, and error rates to make intelligent load balancing decisions.
- Content-Based Routing: It examines the content or characteristics of the incoming request and routes it to a specific server or resource based on predefined rules or criteria. It can be useful for scenarios where different servers specialize in handling specific types of requests.
These are just a few examples of load balancing algorithms, and there are many variations and hybrid approaches that combine multiple algorithms to meet specific requirements. The choice of algorithm depends on factors such as the nature of the workload, server capacities, and desired performance characteristics.
Importance of Load Balancing
Load balancers play a crucial role in enhancing performance and scalability of web applications:
- Increased Capacity: Load balancers enable horizontal scaling by distributing traffic across multiple servers. This approach allows for handling higher loads as the number of servers can be increased or decreased dynamically based on demand.
- Redundancy and High Availability: Load balancers provide redundancy to eliminate a Single Point of Failure (SPOF) by distributing traffic to multiple servers. If one server fails, the load balancer can route requests to the remaining operational servers, ensuring high availability of the application.
- Improved Response Time: By distributing requests based on server capacity and optimizing resource utilization, load balancers help reduce response time. Users experience faster and more responsive applications.
- Scalability: Load balancers enable easy scaling by adding or removing servers without disrupting the overall system. This flexibility allows applications to handle sudden spikes in traffic and accommodate growth seamlessly.
- Session Persistence and Sticky Sessions: Load balancers offer session persistence by ensuring that requests from the same user are routed to the same backend server. This is achieved through techniques such as assigning session cookies or using source IP-based affinity. Session persistence maintains session-related data and provides a consistent user experience.
Firewall
Firewalls are crucial elements of network security that act as a first line of defense against potential threats and unauthorized access. They serve as a protective barrier, monitoring and controlling incoming and outgoing network traffic based on predefined security rules. By enforcing these rules, firewalls help prevent unauthorized access to private networks, safeguard sensitive data, and mitigate potential security risks.
Firewalls work by examining network packets and determining whether to allow or block them based on predefined rulesets. These rules can specify criteria such as source and destination IP addresses, port numbers, protocols, and more. By filtering traffic based on these criteria, firewalls ensure that only authorized and safe connections are permitted while blocking potentially malicious or suspicious traffic.
Here’s how firewalls are involved in the process:
- Network Perimeter Firewall: At the network perimeter, organizations typically deploy firewalls to protect their internal networks from external threats, including incoming internet traffic. When your browser sends a request to “google.com,” the request first goes through the network perimeter firewall. The firewall examines the traffic, filters out potentially malicious requests, and allows only legitimate traffic to pass through to the internal network.
- Web Application Firewall (WAF): Web application firewalls are specifically designed to protect web applications from various attacks, such as SQL injection, cross-site scripting (XSS), and cross-site request forgery (CSRF). In the case of accessing “google.com,” Google’s servers employ WAFs to analyze the incoming requests, inspect the HTTP traffic, and filter out any malicious or suspicious requests. WAFs help safeguard web applications from common vulnerabilities and protect sensitive data.
- Host-based Firewalls: Host-based firewalls are installed on individual devices, such as servers or client machines, to monitor and control their network traffic. These firewalls add an extra layer of security by filtering incoming and outgoing connections at the device level. Host-based firewalls on Google’s servers help protect against unauthorized access attempts and further enhance the security of the web application infrastructure.
How Web Server Software (e.g., Apache, Nginx) Handles the Request
Web servers, such as Apache, Nginx, or Microsoft IIS, are specialized software applications that handle the processing of HTTP requests. These web server software applications are responsible for managing incoming connections, handling the request/response cycle, and ensuring the efficient delivery of web content.
Web server software utilizes various mechanisms to handle requests efficiently. They employ techniques such as multi-threading or event-driven architectures to handle concurrent connections and maximize server performance. These servers are designed to be scalable, allowing them to handle a large number of simultaneous requests.
Web server software also often integrates with other components, such as server-side scripting languages like PHP, Python, or Ruby, to execute server-side logic and generate dynamic content. This enables the server to interact with databases, perform calculations, and process the request in a way that generates the appropriate response.
Additionally, web servers often provide features such as caching, gzip compression, and load balancing. These features enhance performance, improve response times, and ensure high availability and fault tolerance.
Database
When you request a Google.com page, databases play a crucial role behind the scenes in serving the requested content. Here’s how databases come into play in the process:
- Data Storage: Google.com is a complex web application that retrieves and presents vast amounts of information, including search results, images, videos, and more. To handle such a massive volume of data, Google employs databases to store and organize this information efficiently. Databases store various types of data, such as website content, user information, search indexes, and cached data.
- Data Retrieval: When you request a Google.com page, the web application accesses databases to retrieve the relevant information needed to generate the response. For example, when you enter a search query, the application queries the database to retrieve matching search results, incorporating various ranking algorithms and relevancy metrics.
- Caching: To enhance performance and reduce response times, Google employs caching techniques. Frequently accessed or popular data, such as search results, images, and web page snippets, are stored in cache databases. When a request is made, the web application checks the cache first, allowing for faster retrieval and reducing the load on the main databases.
- Data Analysis: Databases also play a vital role in analyzing user behavior and trends. Google utilizes data stored in databases to gain insights into user interactions, search patterns, and other metrics. This analysis helps improve search results, personalize user experiences, and enhance overall service quality.
Behind the scenes, Google utilizes various types of databases, including both relational and NoSQL databases, depending on the specific requirements of different data types and access patterns. These databases work in conjunction with other components, such as web servers, load balancers, and caching systems, to provide a seamless and efficient user experience when accessing Google.com.
Steps involved in processing an HTTP request on the server
- Accepting the Request: The web server accepts the incoming HTTP request from the client and establishes a connection.
- Parsing the Request: The server parses the request to extract important information such as the request method, requested URL, headers, and any other relevant data.
- Routing and Dispatching: The server determines the appropriate route or handler to process the request based on the requested URL and other factors. This step ensures that the request is directed to the correct module or application logic responsible for handling the specific request.
- Executing Server-Side Logic: The server executes the necessary server-side scripts, application logic, or business logic associated with the requested resource. This can include querying databases, retrieving or updating data, performing calculations, or any other processing required to generate the desired response.
- Generating the Response: After executing the server-side logic, the server generates an HTTP response. This includes constructing the response headers, determining the appropriate status code (such as 200 for a successful response), and preparing the response body, which may contain HTML, JSON, or other content.
- Sending the Response: The server sends the generated response back to the client over the established TCP connection. The response includes the response headers and body, which are transmitted in an HTTP response packet.
Receiving and Rendering the Response
Once the client (browser) receives the HTTP response from the server, the process of receiving and rendering the response begins. The HTTP response is the server’s answer to the client’s request and contains the requested web page or resource along with additional metadata. The response plays a crucial role in the final step of delivering the desired content to the user.
Components of an HTTP Response

An HTTP response consists of several components:
- Status Line: The status line provides information about the outcome of the request. It includes a status code, which is a three-digit numerical code that indicates the response’s status, and a corresponding textual phrase that provides a human-readable description. Common status codes include 200 (OK) for a successful response, 404 (Not Found) for a missing resource, and 500 (Internal Server Error) for server-side issues.
- Response Headers: Response headers are additional pieces of metadata sent by the server to provide information about the response. These headers include the content type (e.g., text/html, application/json) that specifies the format of the response body, cache-control directives to control caching behavior, server information, cookies, and more.
- Response Body: The response body contains the actual content of the response, which can be HTML, JSON, XML, images, or any other format based on the request and server-side processing. It represents the web page or resource that the client requested.
Response Process and How the Browser Renders the Page
The process of receiving and rendering the response involves the following steps:
- Parsing the Response: Upon receiving the response, the browser begins by parsing the received data. It examines the status line, response headers, and response body to extract the necessary information.
- Content Interpretation: Based on the content type specified in the response headers, the browser determines how to interpret and handle the response. Different rendering engines are used for different content types. For example, HTML content is rendered by the HTML rendering engine, while images are displayed by the image rendering engine.
- Constructing the Document Object Model (DOM): For HTML responses, the browser constructs the Document Object Model (DOM) from the HTML markup in the response body. The DOM represents the structured representation of the web page, organizing elements like headings, paragraphs, links, and images into a tree-like structure.
- Applying Styles: Once the DOM is constructed, the browser applies CSS styles to the elements based on the CSS rules specified in the response or linked stylesheets. This step determines the visual appearance of the web page, including aspects such as colors, fonts, layouts, and animations.
- Executing JavaScript: If the response includes JavaScript code, the browser executes the JavaScript to perform dynamic actions or manipulate the DOM. JavaScript can add interactivity, handle user input, make asynchronous requests, and modify the content and behavior of the web page.
- Rendering and Displaying the Page: The browser renders the web page by combining the visual styles, layout information, and content from the DOM. It handles rendering optimizations, such as layout and paint optimizations, to efficiently display the content on the screen. Finally, the rendered web page is displayed to the user, allowing them to interact with the content.
Throughout this process, the browser ensures that the web page is rendered accurately and as intended by the web application. It handles the rendering of text, images, forms, links, multimedia content, and other elements that make up the web page, providing an interactive and visually appealing user experience.
Conclusion
In this article, we explored the inner workings of the internet from a technological perspective. We delved into the processes and technologies involved in the journey from typing a URL into our browsers to receiving and rendering the web page. Understanding these concepts is crucial in today’s digital world, where the internet plays a central role in our daily lives.
It allows us to build efficient and scalable web applications, ensures smooth user experiences, and enables us to troubleshoot issues effectively.
In conclusion, the internet is a complex and interconnected network of systems, protocols, and technologies. From domain name resolution to establishing connections, processing requests, generating responses, and rendering web pages, every step is orchestrated to provide us with seamless access to information and services. By grasping the software engineering perspective of the internet, we gain a deeper appreciation for the underlying mechanisms that make this vast network function. It empowers us to navigate the digital landscape with confidence, contribute to its evolution, and make the most of its limitless possibilities.